
Вадим Лукомский все объяснит.

На пресс-конференцию в понедельник Микель Артета пришел вооруженным. Испанец попытался обосновать последние неудачи «Арсенала» невезением – при этом привел конкретные цифры. Разницу между вероятностью победы, которую давала клубная модель, и реальными результатами.
«В прошлом году мы обыграли «Эвертон», имея лишь 25-процентный шанс на победу. Мы победили 3:2. В прошлые выходные у нас был 67-процентный шанс на победу и всего 9-процентный шанс на поражение. И мы проиграли. Против «Бернли» наш шанс на поражение составлял всего 3%, но мы проиграли. Против «Тоттенхэма» – 7%, но мы проиграли», – объяснил испанец.
Откуда вообще берутся такие проценты?
Практически любая статистическая модель позволяет симулировать матч на основании базового показателя. С помощью большого количества симуляций можно выяснить вероятности трех исходов (ничья, победа, поражение). В зависимости от особенностей модели базовый показатель может быть разным, но для простоты объяснения давайте представим, что речь про обычную xG-модель. На ее примере разберемся в методологии
Итак, у нас есть данные по xG за матч (и, следовательно, данные об остроте каждого удара). Далее на основании информации об остроте и последовательности ударов симулируется счет. Чем больше опасных ударов, тем больше вероятность победы. При этом одна конкретная симуляция может завершиться с любым исходом. Достоверная картина получается из очень большого числа симуляций (обычно 1000 достаточно).
То есть 67-процентный шанс означает, что 670 из 1000 симуляций завершились победой команды. Это вполне полезные цифры при условии, что мы считаем модель рабочей. Хотя сильно новой информации они не дают. Просто переводят данные в формат процентов, разделенных на три результата. Обычно эти проценты используют вместе с графиком xG для полноты картины:
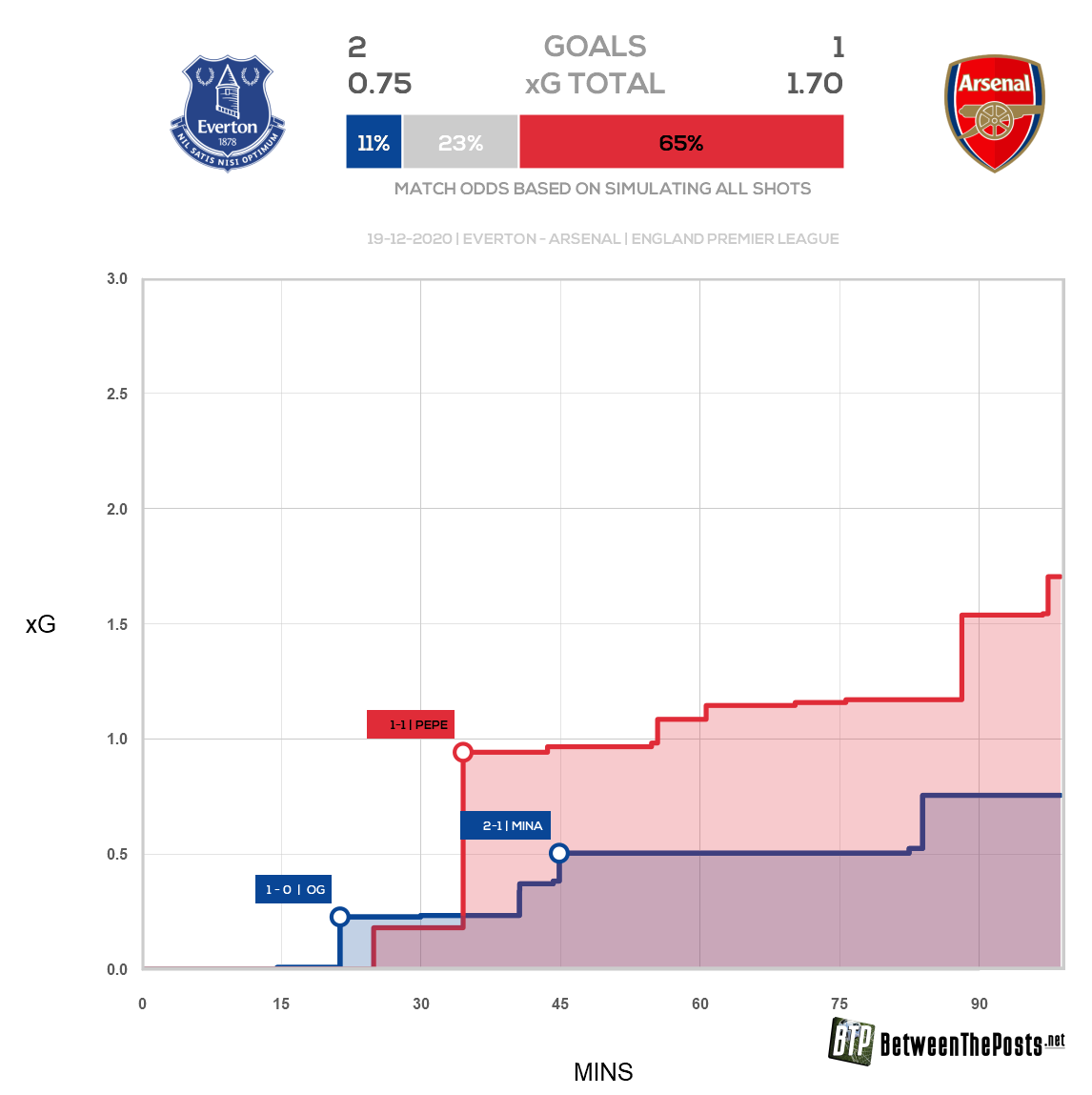
Не факт, что модель, о которой говорит Артета, основана именно на xG. Почти наверняка она труднее. «Арсенал» владеет собственной статистической компанией StatDNA. Арсен Венгер в 2015-м году был одним из первых, кто публично упомянул ожидаемые голы. С тех пор даже открытые модели шагнули вперед.
Один из вариантов: модель «Арсенала» может оценивать вероятность не на основании каждого удара, а на основании продвижения в каждой конкретной атаке. Вариаций может быть очень много – гадать бессмысленно. Но два промежуточных итога напрашиваются: 1) вероятно, речь о более продвинутой модели, чем xG из публичного доступа; 2) сам принцип получения процентов, которые дошли до Артеты, тот же.
Мог ли Артета ошибиться (или даже соврать)?
Здесь начинается самое интересное. Данные по матчу с «Эвертоном» (картинка выше) действительно похожи. Артета говорит о 67% на победу и 9% на поражение. Общедоступная xG-модель от сайта BetweenThePosts дала схожий результат: 11% на победу «Эвертона» и 65% на «Арсенал». Расхождения вполне можно списать на более высокую точность модели «Арсенала».
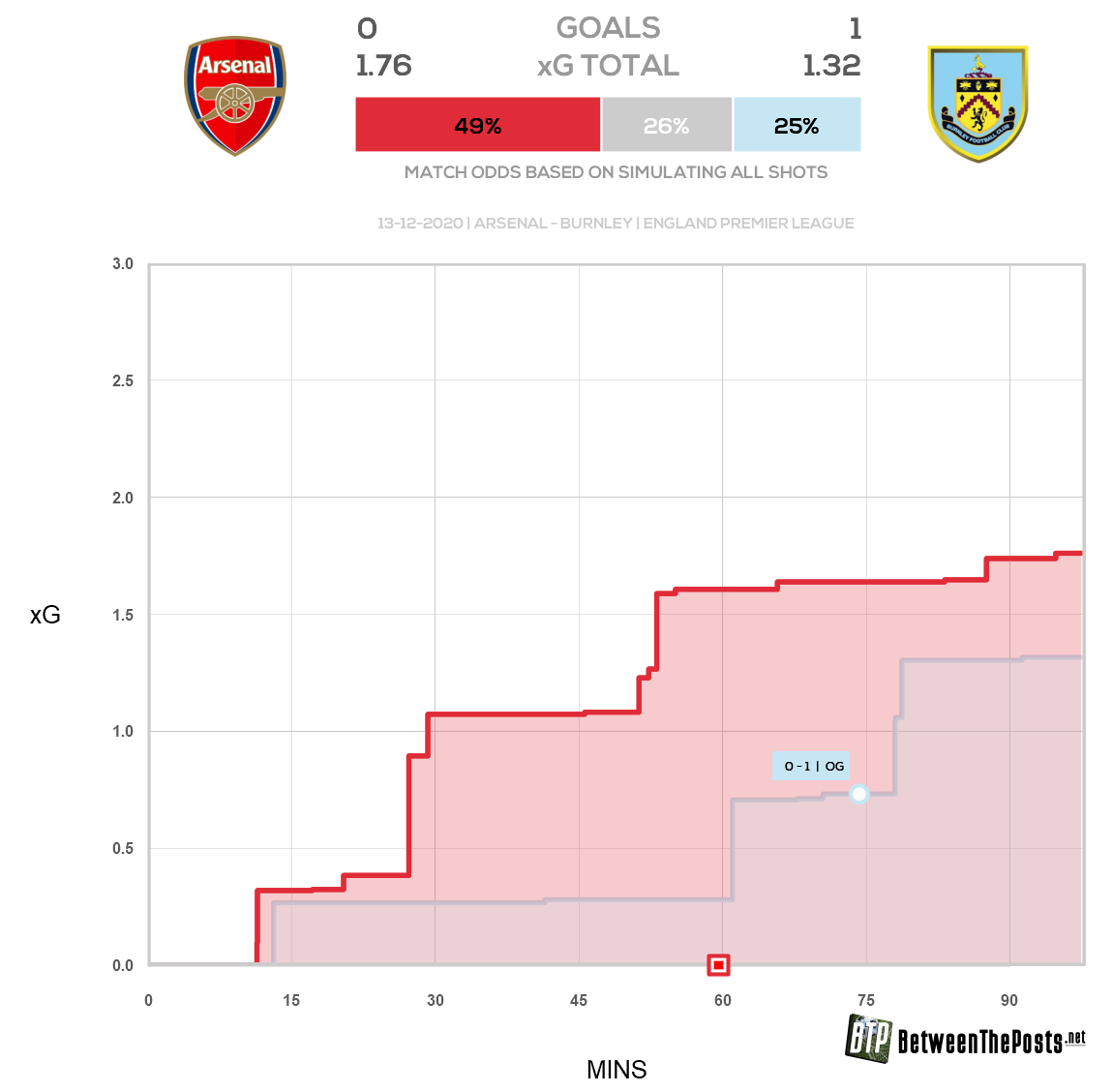
А вот дальше начинаются странности. «Бернли»: по Артете шанс на поражение составлял 3%, а xG-модель дает 25%.
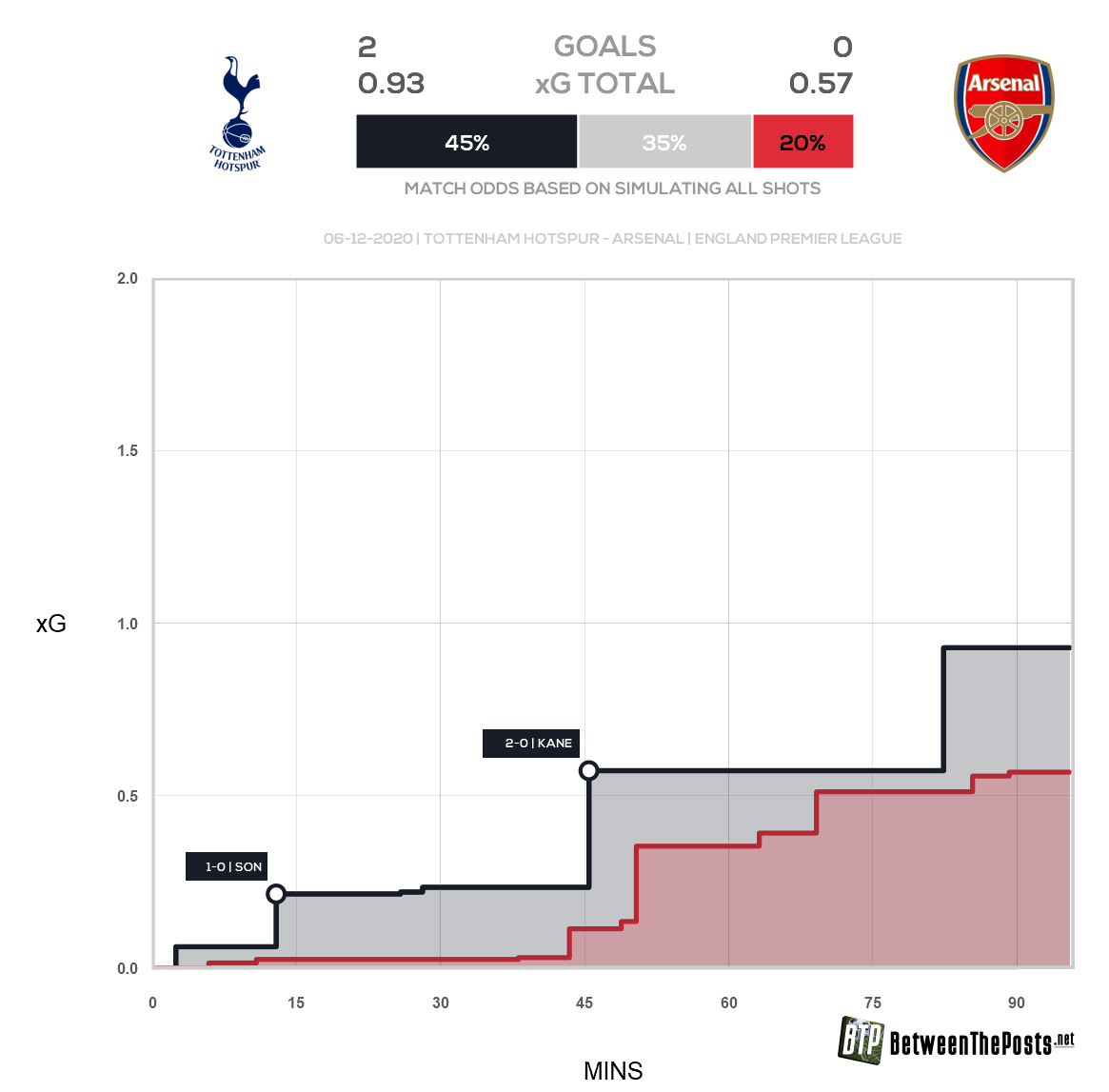
«Тоттенхэм»: по Артете шанс на поражение всего 7%, а xG-модель дает 45%.
Потенциальное объяснение: дикая заточенность модели «Арсенала» на non-shot – вместо чистой ориентации на удары берутся потенциально острые действия вблизи и внутри штрафной. В открытом доступе есть одна non-shot xG-модель от сайта FiveThirtyEight.
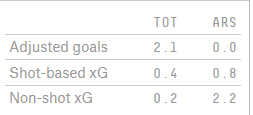

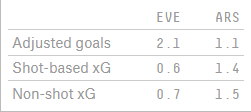
В матче с «Эвертоном» мы видим похожие результаты обычной модели и non-shot. А вот с «Тоттенхэмом» и «Бернли» у команды Артеты был перевес именно за счет действий, которые до удара не довели. Возможно, симуляции «Арсенала» проводились с акцентом на эту метрику (или схожую). Это все равно не объясняет таких диких расхождений, но приближает нас к тому, что в голове у Артеты.
Перед нами возникает пара вопросов. Разумно ли приводить данные модели, не уточняя, что это за модель и на чем она основывается? Нет, конечно. Мы тут весело погадали – и даже уловили направление, в котором нужно рыть дальше, но убедительности спикеру это не добавляет (если цель, конечно, донести точку зрения, а не выпендриться через использование цифр).
Разумно ли оценивать «Арсенал» с акцентом на non-shot-действия? Зависит от того, насколько умная модель используется, но при прочих равных – нет. В большом разборе проблем я подчеркивал особенность атаки «Арсенала»: «Команда на 5-м месте по входам на чужую треть и точным пасам в штрафную. Обычно этот показатель коррелирует с числом созданных моментов. Но не в случае команды Артеты – вместо плюс-минус 5-й атаки у них 15-я по ожидаемым голам и 16-я по ударам».
Для большинства команд связь намного более прямая. Следовательно, данные по non-shot были бы уместными. Для «Арсенала» на большой дистанции корреляции почти не наблюдается. Причина в чудовищно медленных розыгрышах (о них подробнее в том же тексте).

А теперь самый важный вопрос: разумно ли вообще использовать такие модели на дистанции пары матчей? Однозначно – нет. Две основные причины:
1. На такой короткой дистанции тяжело отделить погрешности модели от невезения. Пару лет назад математик Дэвид Самптер объяснил это в мини-исследовании с помощью распределения Пуассона. Его заключение: дистанция 1-2 матча непригодна для анализа и именно статистических выводов; только с дистанции 3-6 матчей начинают вырисовываться тренды, но в идеале нужно еще больше.
2. Такое количество матчей не так уж трудно посмотреть (и оценить влияние везения и невезения). Ценность подобных моделей именно в охвате огромного массива данных. Лишь на дистанции проявляются тенденций, а расхождения между реальными результатами и результатами модели становятся более существенными. Достаточно существенными, чтобы говорить о невезении.
Артета не просто использовал данные на слишком малой выборке, но еще выдернул из нее выгодные матчи. Не упомянув про игру с «Саутгемптоном», которая тоже уместилась в этот отрезок.
На выходе:
• Спасибо Артете за попытку использовать данные и теорию вероятностей для более глубокого понимания результатов.
• На мой взгляд, Микель допустил несколько критичных ошибок (или даже умышленных манипуляций) при интерпретации данных. Не упомянул, на чем основана модель, из которой получены проценты; попытался указать на невезение, но при этом использовал слишком малую выборку матчей; вообще проигнорировал невыгодный матч с «Саутгемптоном»; взял модель, которая оценивает «Арсенал» лучше, чем практически любая другая (вероятно, переоценивает из-за особенностей стиля).
• Конечно, нельзя исключать, что это в первую очередь посыл игрокам. Что манипуляции тут именно для того, чтобы показать им, что все не так плохо и что команде не везет. Эффективность этого мы сможем оценить только через определенное время.

• Артета взял самые выгодные для его команды цифры и дико приукрасил ситуацию. Но в сути не ошибся. «Арсенал» в этих матчах не был так плох как кажется из результатов. Поражения против «Эвертона» и «Бернли» кажутся слишком суровым исходом (тут и данные других моделей подтверждают, и мои скромные ощущения от просмотра этих игр). Но опять же – это малая выборка, чтобы подтягивать тезис о глобальном невезении. Если мы возьмем всю дистанцию сезона, то найдем и фартовые победы «Арсенала» (например, против «Вест Хэма»). Именно поэтому важно учитывать большую выборку матчей перед тем, как делать громкие выводы.















